

Cloudera Enterprise is a modern platform for Machine learning services and analytics optimized for the cloud. It can deploy and manage multi-disciplinary applications on the cloud, without sacrificing security governance and metadata management.
These multi-disciplinary analytical Applications can run anywhere – on-premises or on a cloud.
Cloudera Enterprise has focused on four core Analytical Applications:
- Data Engineering
- Data Science
- Data Warehouse
- Operational Database
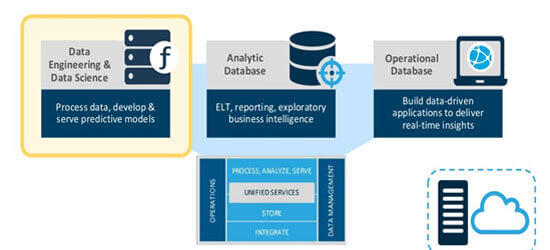
Cloudera Data Science & Data Engineering
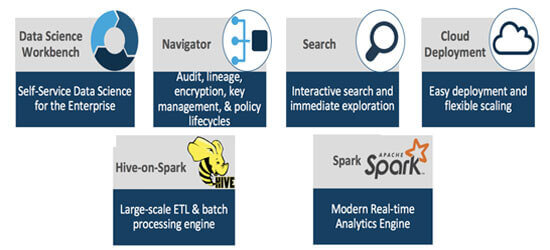
1) Cloudera Data Engineering
Requirements of Data Engineering
- Hybrid support for multiple environments.
- Unified platform from ingest to insights.
- Transient workloads for flexibility, lower the TCO and risk.
Cloudera Enterprise offers a managed cloud service for data engineering and ETL workloads.
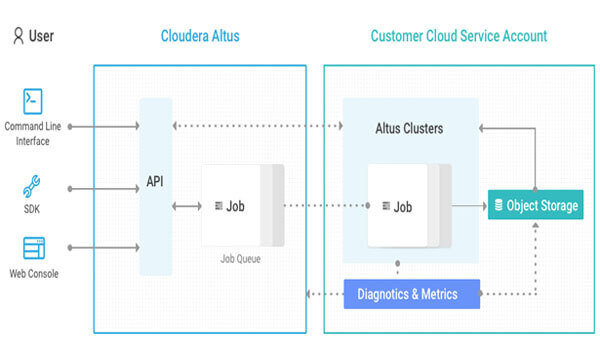
Altus Data Engineering enables you to create clusters and run jobs for data science and engineering workloads.
Altus offers multiple distributed processing engine options, including Hive, Spark, and MapReduce2 (MR2), for different data engineering workloads.
The below diagram shows the architecture and process flow of Altus Data Engineering:
Cloudera Altus Data Engineering platform is backed by the following set of core, components:-
- Hive
- Spark 2
- Map Reduce 2
- Spark or PySpark
- Impala
2) Cloudera Data Science Workbench
Cloudera Data Science WorkBench (CDSW) is a secured, self-service Data science platform that lets data scientists manage analytics pipelines, to securely run computations on data in Hadoop clusters.
With Cloudera Data Science Workbench, you can deploy the complete lifecycle of a machine learning project right from research to deployment.
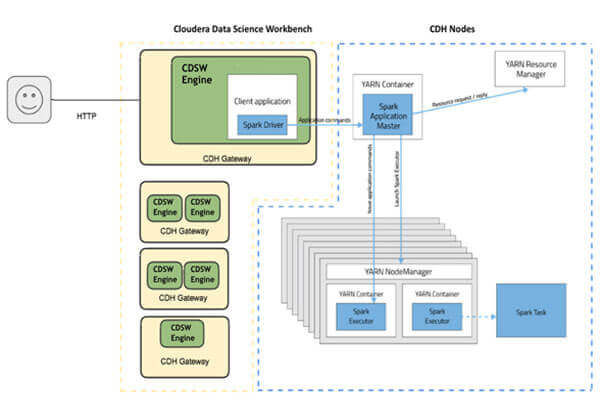
CDSW Architecture:
Cloudera Data Science Workbench runs on one or more dedicated gateway hosts on CDH clusters. Each of these hosts has the Cloudera Manager Agent installed on them.
CDSW core Capabilities:
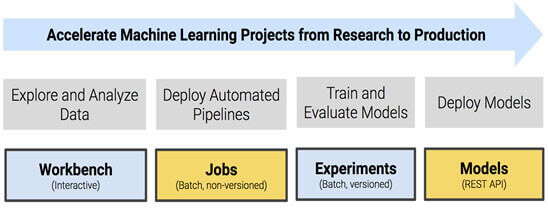
1) Projects
Organizes your data science development consulting services related projects that include reusable code, configuration, artifacts, and libraries.
2) Workbench
Allows interactive user sessions with Python, R, and Scala using flexible engines. Sharing, publishing, and collaboration of projects and results is possible.
3) Jobs
Automate analytics workloads with the jobs and pipeline scheduling system that supports real-time monitoring, job history, and email alerts.
4) Experiments
Use batch jobs to train and compare versioned, reproducible models.
5) Models
Deploy and serve models as REST APIs. Allows data scientists to test and share the model.
3) Cloudera Data Warehouse
Cloudera's modern Data Warehouse powers high-performance BI and data warehousing consulting, with efficient security and governance.
It’s an auto-scaling and cost effective hybrid, multi-cloud analytics solution that ingests data anywhere, at massive scale, from structured, semi-structured, and unstructured and edge sources.
It seamlessly moves on-premises workloads to the cloud for reports, dashboards, ad-hoc and advanced analytics.
Traditional Data Warehouse vs. Enterprise Data Warehouse

Cloudera Altus Data Warehouse, a modern data warehouse, built with hybrid, cloud-native architecture.
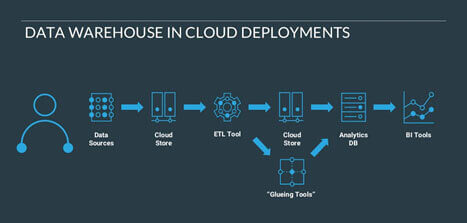
Cloudera EDW deals with,
More people- 1000’s of new users and new usecases at all skills levels: Machine learning, Analytics and Data science.
More Data- Handles massive amount of new data and data sources.
More Workloads- 100’s of Production grade deployments with complete security and governance.
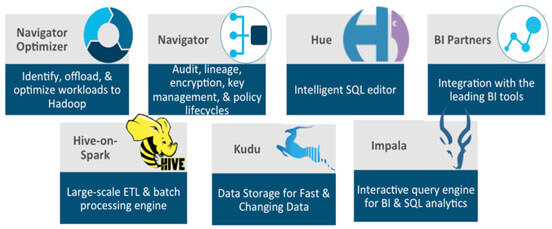
The Analytic DB has specific components:-
- Hue
- Cloudera Navigator
- Hive
- Spark
- Kudu
- Impala
4) Operational Database
Cloudera takes an operational database that provides traditional structured data alongside latest unstructured data within a unified open-source platform.
The Operational DB helps you to:-
- Operationalize machine learning/artificial intelligence to revolutionize sectors such as healthcare, public utilities and so on
- Serves real-time content at webscale
- Empower big data analytics solutions for operational and offline uses.
- Use as a resilient store of record
Cloudera Operational Database provides a flexible operational database platform, capable of batch and stream processing. It supports RDBMS and NoSQL storage layers and has the ability to store an unlimited amount of structured semi-structured and unstructured data.
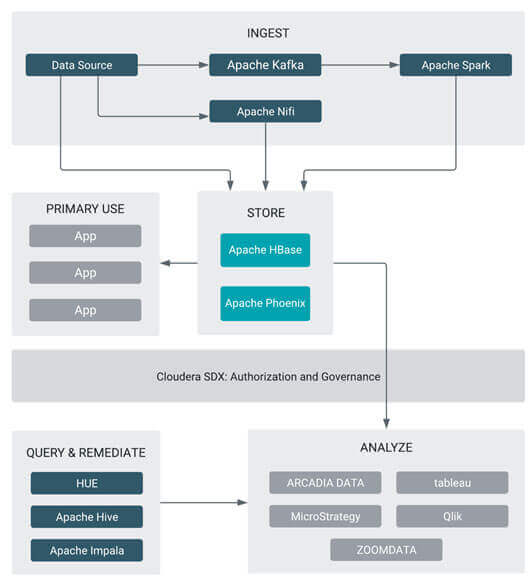
Cloudera Operational DB Architecture on cloud
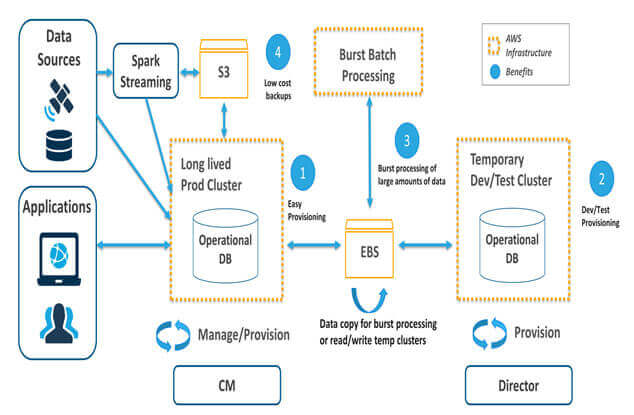
Operational database jobs use HBase to perform fast searches on very large datasets. They can also use Spark Streaming to feed streaming data into HBase. Mostly, operational database jobs run on highly available long-running clusters which is backed up by local storage with HDFS.
Consider the following Diagram.
Conclusion
You should now have a good understanding about Cloudera’s core workloads patterns that can run on-premises as well as cloud. Cloudera has made it easy for the administrators, Data engineers and Data scientists to work on multiple workloads at a centralized location.

