
Apache Spark Consulting Services
Apache Spark solutions enable processing vast streams of data at lightning-fast speed. Discover better insights, identify patterns, complement the real-time data analysis and allow simultaneous data operations with our defined Apache Spark services.













Profound Apache Spark Consulting
Apache Spark is an open-source computing framework that is specially designed to manage a large volume of data processing and analytics. Every industry in the current times definitely needs the inputs from data to accomplish to grow better. This is where Apache Spark fulfils the need for a robust data management system with its unique processing abilities. We help you to adapt to Apache Spark from your existing data systems and have a single point of access with integrated data benefits. Our Apache Spark consulting services are just what you need to get clarity and guidance on how well this new data management system can transform your enterprise’s approach to data for good.
Swift Processing Speed
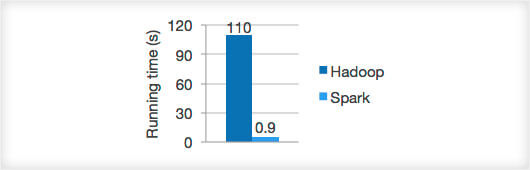
As Apache Spark uses in-memory computing by storing the data in the RDDs, it can run about 100x faster with data in memory and 10x quicker for data in the disk.

Ease of Use
Apache Spark has simplified the data management process with the inclusion of several APIs and over 80 high-level operators with the ability to write in Java, R, Python, Scala and SQL.
Advanced Analytics
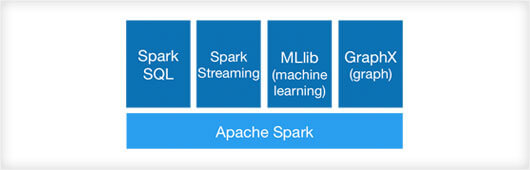
Apache Spark has dedicated libraries for different data operations like data streaming, machine learning, graph algorithms and SQL queries aside from the tools for MAP and reduction.

Supported on Diverse Systems
You can run Apache Spark as a standalone system in its cluster mode or also on Hadoop, Mesos and Kubernetes and access data from other systems like Apache HBase, Hive and many others.
We deliver Apache Spark Services across
Redefining Apache Spark Solutions
Apache Spark is a valuable tool for diverse data computing needs with its unique framework that efficiently manages complex algorithms. Apache Spark solutions are best for those companies that have a massive volume of data and need quick data insights and real-time data streaming capabilities with a need to encompass the growing data volumes. Apache Spark can efficiently run multiple data operations in parallel at a higher speed than most other systems. Our Apache Spark services are designed to help organizations utilize the best features of Spark for better data processing.
Ultra-Fast Operations
Apache Spark can process data much faster than most data processing systems, which helps you to stay a step ahead of your competition in analyzing the industry trends.
In-Memory Computation
Due to its in-memory computation, Apache Spark functions as a powerful data center and makes it possible to analyze large datasets in a short time with multiple supported analytics.
Highly Secure System
Apache Spark is part of the HDP and therefore, it also has the high-level security features like the AES encryption to keep your data safe like the Hadoop platforms.
Business-Specific Apache Spark Consulting Services
If the extensive data processing is what you need, then Apache Spark is the best system for your applications. As it can be easily integrated with various other Hadoop products, you can facilitate seamless access and transfer of data between multiple systems at a breakneck pace. There are numerous ways by which you can use Apache Spark as required for your business. Our Apache Spark consulting services are designed to foster a data-driven culture within organizations and support data warehouse consulting initiatives for better data utilization.
Deliver Quick Insights
With real-time analytics, you can get the insights faster from the accurate data analytics system that helps in faster implementations.
Easy Migration
If you are using the traditional ETL systems, you can effortlessly migrate to Apache Spark to enjoy faster memory processing.
Predictive Analysis
Combined with the machine learning library, Apache Spark helps in the intelligent decision-making process that keeps the business ready from surprises.
Apache Spark Implementation
Traditional systems are falling short nowadays when it comes to big data analysis due to the lack of storage space or exorbitant storage costs. Apache Spark provides a unified solution for common big data challenges with high-performance in-memory computing, supporting scalable data warehouse services for real-time decision-making. With Apache Spark implementation, you have complete flexibility to run multiple operations on any system and facilitate simultaneous interaction between datasets.
Fast Workload Performance
Apache Spark has smart provisions for storing and accessing objects with options for split computations, multiple caching layers, capabilities for setting alerts and insights, the ability to batch of writes, SSD caching and pre-fetching objects for quick implementation.

Big Data Real-Time Streaming
You can cut out the time taken to access the data from the storage system of the HDFS and directly bring the data from multiple sources to the Apache Spark platform and execute the big data analysis for real-time processing.

Real-Time User Profiling
You can create a simple real-time dashboard in Apache Spark with scalable and incremental data profiling of the customers. You can transform unstructured datasets into specific profiles in real-time that further empowers your insights.

Seamless Integration
During the Apache Spark implementation, you can integrate it easily with the existing systems, datasets and tools like the ODBC drivers, REST APIs, SQL Server, Oracle DB, MySQL and many other database connectors.

Features and Capabilities of Apache Spark Services
Apache Spark is based on the Hadoop MapReduce, wherein it further elevates the MapReduce to use it for computations and real-time data processing. Spark can manage simultaneously a wide range of operations like batch processing, real-time data processing, iterative processes, sophisticated algorithms and queries. Developed in the year 2009 in UC Berkeley’s AMPLab by Matei Zaharia, Apache Spark was donated to Apache Software Foundation in 2013 and soon became a top-level project in a year.
Standalone, Yarn or SIMR
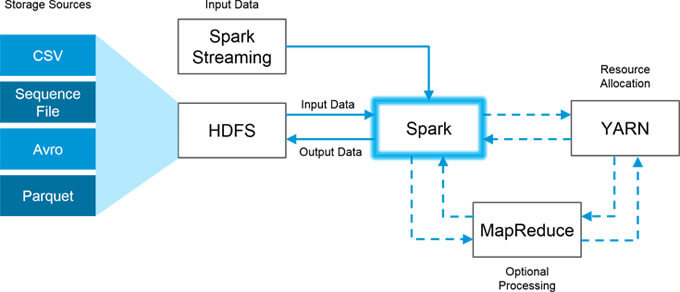
Apache Spark can be deployed in three ways – as an independent system with HDFS, on Hadoop Yarn without any root access or launch as Spark in Map Reduce (SIMR).
Running Spark on Mesos
Apache Spark can be run on Apache Mesos in a cluster system where the Mesos master will replace Spark master as the cluster manager and manage all systems in the infrastructure.
Multi-Language Support
Apache Spark allows algorithms to be written in some common languages like Python, R and Scala, among many others, which allows for great flexibility with the developers.
Spark Streaming
As a part of the Apache Spark Core, Spark Streaming works by processing the data in small batches with transformations based on the Resilient Distributed Datasets (RDDs).
Spark SQL
Spark SQL is a component in the Core that provides the much-needed support for the semi-structured and structured data for the data processing and helps with integrations.
GraphX
GraphX provides the API for graphics computation through its distributed graph-processing framework. You can combine and view different graphs on a single system for better analysis.
Apache Spark Use Cases
Apache Spark has made itself useful for various functions across all business verticals. From the automated systems to creating customer profiles, Apache Spark has made the business process simpler and time-efficient for the organizations.
We have helped many organizations with our Apache Spark Services that have positioned them to make informed business decisions based on data.
Banking & Finance
Organizations in the finance sectors can use Apache Spark for risk assessment, customer profiling, targeted advertising, consolidated operation view, detect fraudulent transactions and use real-time monitoring systems for potential issues.
Retail & E-Commerce
Apache Spark helps in implementing the cluster algorithms with data from social media, advertisements, customer actions on websites, product reviews and many more to enhance customer service.
Travel & Hospitality
Apache Spark has reduced the runtime it takes for the travel applications to complete a booking. Further, it can also be used to personalize the recommendations, real-time data processing and related searches.
Healthcare
Many healthcare organizations have started using Apache Spark as a single integrated system to record information on patients, inventories, vendors and other clinical data and analyze ways to reduce costs.
Logistics
Organizations can use the real-time data analysis and user profiles of Apache Spark to forecast the demands, predict the issues and prepare themselves to plan out the logistics by combating the problems.
Media & Entertainment
Companies are using Spark to personalize the content according to the customers, leverage customer profiles to create interesting content and targeted ads, and quickly publish news with minimal process.
Other Big Data & Analytics Services
Top Services
Trending Services
Frequently Asked Questions
Get your questions on Apache Spark cleared now.
You can run Spark in the standalone mode, but if you are running it in the form of clusters, then you may use a shared system to support the data access from different sources.
Apache Spark is an efficient system only if it is put to use right. We have helped organizations to deal with various challenges with Apache Spark like:
- - Setting up proper Spark configuration to ensure that the in-memory computation works seamlessly.
- - Ensure the smooth processing of IoT streams even when the number of streams increases.
- - Speed up the data processing even further by tuning the Spark SQL.
- - Analyze the overall data process and provide Apache Spark consulting for high performance.
If you have any other issues, our experts can help you with that too.
Yes, of course. We can help you with migrating to Spark and in setting up the Spark system with customized algorithms based on the functions, you require from Spark.
Spark works on the concept of spill data to disk when it doesn’t fit into the memory space. Therefore, you don’t need to worry about the growing data volumes as data will automatically accommodate itself and provide a high-speed performance no matter where it is stored.
Yes, we provide various Apache Spark services, one of them being re-engineering and additional data stream setup. If you are currently using Spark and require setting up new processes, then we can facilitate in creating new algorithms and data streams to manage the data processing based on the expected outcomes.
Spark NLP is an open source NLP library built natively on Apache Spark and TensorFlow.